Quicksort
| Developed by Hardeep Singh | |
| Copyright | © Hardeep Singh, 2000-2008 |
| seeingwithc@hotmail.com | |
| Website | SeeingWithC.org |
| All rights reserved. | |
| The code may not be used commercially without permission. | |
| The code does not come with any warranties, explicit or implied. | |
| The code cannot be distributed without this header. | |
Various algorithms exist for the sorting of a given list of numbers/strings. Some of the algorithms are quite simple such as bubble sort, while others are more complex. Each algorithm has its own pros and cons, and no single algorithm can be nominated as the best. Quicksort is one of the well known sorting algorithms and is the subject of this writeup.
Problem: We are given a set of numbers that must be arranged in non-decreasing order. We need to use Quicksort for the solution.
Note: In the text below, lg(n) means log of n to base 2.
Solution #1: Basic Quicksort, recursive.
Quicksort was developed by C.A.R. Hoare and is a widely used sorting technique, based on divide and conquer. It is an O(n*n) algorithm in the worst case, which is as bad as insertion and selection sorts. However, its popularity derives from the fact that it has an excellent average case behaviour of O(n*log(n)). In practice, Quicksort almost always achieves this behaviour.
Quicksort first selects an element that is to be used as split-point from the list of given numbers. All the numbers smaller than the split-point are brought to one side of the list and the rest on the other. This operation is called splitting.
Consider the list: 4 3 1 7 5 9 6 2 8
Now, assume the first element of the list, 4 as the split-point. Then, after splitting the list will be arranged as:
3 1 2 4 7 5 9 6 8
Or in some other order, say: 2 3 1 4 ...
That is, the exact order is immaterial. What is important is that the order should be:
After this, the list is divided into lists, one containing the elements less than the split-point element and the other containing the elements more than the split-point element. These two lists are again individually sorted using Quicksort, that is by again finding a split-point and dividing into two parts etc. In the program given below, we will let recursion sort the smaller lists.
In the example, the two sub-lists, are:
2 3 1 and 7 5 9 6 8.
Let us consider another example, this time in more detail.
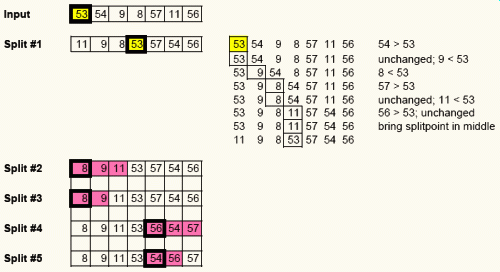
The list to be sorted is shown at the top. The situation after each of the split operations is also shown, and for the first split - all the comparison-exchanges are shown in more detail. The number with a bold square around it is the split point and the part of the list shown in pink is the part thats being worked upon in that split operation.
In the original list 53 is chosen as the split point. One by one each number is compared to the split point. If its greater, the list is left as is. If not, the splitpoint is moved one step to the right and the number in consideration exchanged with the splitpoint.
At the end of the split operation, the splitpoint element is brought into the middle.
Please make sure at this point you understand how the splitting is happening, based on the drawing above.
Now let us see the program:
#include <stdio.h>
#define MAXELT 50
typedef int key;
typedef int index;
key list[MAXELT];
void main()
{
int i=-1,j,n;
char t[10];
void quicksort(index,index);
do { //read the list of numbers
if (i!=-1)
list[i++]=n;
else
i++;
printf("\nEnter the numbers <End by #>");
fflush(stdin);
scanf("%[^\n]",t);
if (sscanf(t,"%d",&n)<1)
break;
} while (1);
quicksort(0,i-1); //sort
printf("The list obtained is "); //print
for (j=0;j<i;j++)
printf("\n %d",list[j]);
}
void quicksort(index first,index last)
{
void split(index,index,index*);
index splitpoint;
if (first<last) {
split(first,last,&splitpoint); //split
quicksort(first,splitpoint-1); //sort the first sub-list
quicksort(splitpoint+1,last); //sort the second sub-list
}
}
void split(index first,index last,index *splitpoint)
{
key x;
index unknown;
void interchange(int*,int*);
x=list[first]; //find the split-point element
*splitpoint=first; //find the splitpoint
for (unknown=first+1;unknown<=last;unknown++) {
//move through the list
if (list[unknown]<x) { //comparing each element
//with the split-point element
*splitpoint=(*splitpoint)+1;
//move the splitpoint
interchange(&list[*splitpoint],&list[unknown]);
//move the split-point element
}
}
interchange(&list[first],&list[*splitpoint]);
//get the split-point element
//in the middle
return;
}
void interchange(int *x,int *y) //interchange
{
int temp;
temp=*x;
*x=*y;
*y=temp;
}
//solution 1 ends
As you can see, Quicksort is not an inplace sort, since it needs extra space to store the recursion stack. Also, it has a very bad worst case behaviour. As implemented above, the worst case occurs when the list is already in order, or if it is in the reverse order. This makes Quicksort an unnatural sort, since it has to do most work when all the work is already done! However, in practice, Quicksort works quite well. You can include counters to count the number of key-comparisons/swaps done to find its behaviour and test it with different types of input data. The amount of extra storage space needed is O(n).
Quicksort can keep doing swaps of elements with equal keys. At times it may be important that equal keys remain in the same order as in the original list. So, to avoid this, the following scheme may be used:
'Attach to each record its sequence number in the original file. This number is made a part of the key in such a way that it is the least significant part. This keeps the records in the same relative order as they were in input.'
In particular, all keys can be changed from A(i) to A(i)*n+i (i starts from zero) to make all keys distinct. This, after sorting can be changed to floor(A(i)/n). The equal keys will be in the same relative order as before.
Solution #1: Modifed Quicksort, non-recursive.
In our second attempt towards implementation we
will make a number of improvements:
Let us look at the program:
#include <stdio.h>
#define MAXELT 100
#define INFINITY 32760 //numbers in list should not exceed
//this. change the value to suit your
//needs
#define SMALLSIZE 10 //not less than 3
#define STACKSIZE 100 //should be ceiling(lg(MAXSIZE)+1)
int list[MAXELT+1]; //one extra, to hold INFINITY
struct { //stack element.
int a,b;
} stack[STACKSIZE];
int top=-1; //initialise stack
void main() //overhead!
{
int i=-1,j,n;
char t[10];
void quicksort(int);
do {
if (i!=-1)
list[i++]=n;
else
i++;
printf("\nEnter the numbers <End by #>");
fflush(stdin);
scanf("%[^\n]",t);
if (sscanf(t,"%d",&n)<1)
break;
} while (1);
quicksort(i-1);
printf("The list obtained is ");
for (j=0;j<i;j++)
printf("\n %d",list[j]);
}
void interchange(int *x,int *y) //swap
{
int temp;
temp=*x;
*x=*y;
*y=temp;
}
void split(int first,int last,int *splitpoint)
{
int x,i,j,s,g;
//here, atleast three elements are needed
if (list[first]<list[(first+last)/2]) { //find median
s=first;
g=(first+last)/2;
}
else {
g=first;
s=(first+last)/2;
}
if (list[last]<=list[s])
x=s;
else if (list[last]<=list[g])
x=last;
else
x=g;
interchange(&list[x],&list[first]); //swap the split-point element
//with the first
x=list[first];
i=first; //initialise
j=last+1;
while (i<j) {
do { //find j
j--;
} while (list[j]>x);
do {
i++; //find i
} while (list[i]<x);
interchange(&list[i],&list[j]); //swap
}
interchange(&list[i],&list[j]); //undo the extra swap
interchange(&list[first],&list[j]); //bring the split-point
//element to the first
*splitpoint=j;
}
void push(int a,int b) //push
{
top++;
stack[top].a=a;
stack[top].b=b;
}
void pop(int *a,int *b) //pop
{
*a=stack[top].a;
*b=stack[top].b;
top--;
}
void insertion_sort(int first,int last)
{
int i,j,c;
for (i=first;i<=last;i++) {
j=list[i];
c=i;
while ((list[c-1]>j)&&(c>first)) {
list[c]=list[c-1];
c--;
}
list[c]=j;
}
}
void quicksort(int n)
{
int first,last,splitpoint;
push(0,n);
while (top!=-1) {
pop(&first,&last);
for (;;) {
if (last-first>SMALLSIZE) {
//find the larger sub-list
split(first,last,&splitpoint);
//push the smaller list
if (last-splitpoint<splitpoint-first) {
push(first,splitpoint-1);
first=splitpoint+1;
}
else {
push(splitpoint+1,last);
last=splitpoint-1;
}
}
else { //sort the smaller sub-lists
//through insertion sort
insertion_sort(first,last);
break;
}
}
} //iterate for larger list
}
//end of solution 2
The program removes many disadvantages of the previous program. Still, it is not necessarily an improvement. While using Quicksort for your own problem, think before using the second program. If your language implements recursion well, you may decide to go for a recursive version. However, you may decide to use the median-of-three and the look-before-pushing-in-stack improvements. Also, you may decide to keep one recursive call and remove only tail recursion which is more in-efficient and easier to remove without stack. You can also consider which of the two split functions to use. The first one does not need the INFINITY mark at the end of the list. However, it is slightly slower.
The way this program is written, the stack never requires more than 2*ceiling(lg(n)). If we want to save the extra comparison in determining the larger sub-list, we need to store only the 'first' of the new list on the stack. (If we work immediately on the second sub-list, the second of the first sub-list can be known from the first of the second sub-list by subtracting 2).
Even in this case, one of the first and the last can be saved (depending on the sub-list on which we work immediately) with either a boolean variable to tell us what is stored or using a negative value of the index.
Now, for a comparison between the two programs. I created two different lists, each containing 10000 numbers (numbers selected randomly from between 1 and 10000). The first implementation took 2880275 and 158007 comparisons respectively. The second implementation took around 128395 and 143583 comparisons.
This indicates that the worst case behaviour has improved with the changes we made, as we thought they would. Have a look at this graphs.
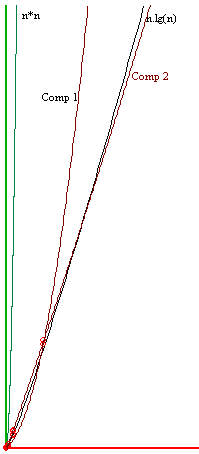
While the first implementation is somewhere midway between O(n*n) and O(nlog(n)), the second implementation is much close to O(nlog(n)). Beautiful, isnt it? (The graphs have been created using HSB Grapher).
So much for sorting! Thanks for reading.
![]()