Finding the Largest and Second Largest Problem
| Developed by Hardeep Singh | |
| Copyright | © Hardeep Singh, 2000-2009 |
| seeingwithc@hotmail.com | |
| Website | SeeingWithC.org |
| Some rights reserved. As of March 28th 2009, this code is released under GNU General Public License version 3. | |
| The code does not come with any warranties, explicit or implied. | |
| The code cannot be distributed without this header. | |
Problem: We are given a set of numbers, in any random order and we must find the largest and the second largest numbers of the set.
The problem appears to be quite simple but we will discover some newer and faster ways of doing this. Also in the course of this article we will find that the method used to award the second prize in tennis tournaments is unfair.
Note: In the text below, lg(n) means log of n to base 2.
Solution #1: Naive approach.
On first look, this problem appears to be quite simple. Indeed, the solution is possible through a very simple approach: Find the largest of the set, eliminate it and again find the largest of the remainder of the elements.
First we have a look at an implementation of this method (advanced readers may skip).
#include <stdio.h>
#define MAXELT 10001
void main()
{
int i=-1,n=0,largest,slargest;
char t[10];
void largest_and_second_largest(int[],int,int&,int&);
int list[MAXELT];
do { //read the list of numbers
if (i!=-1)
list[i++]=n;
else
i++;
printf("\nEnter the numbers <End by #>");
gets(t);
if (sscanf(t,"%d",&n)<1)
break;
} while (1);
largest_and_second_largest(list,i,largest,slargest);
printf("The largest of the list is %d and the second largest is %d.",largest,slargest);
}
//pre: there must be atleast two numbers in the list
void largest_and_second_largest(int list[],int n,int &largest,int &slargest)
{
int largeindex=0,i;
largest=list[0];
for (i=1;i<n;i++) //find the largest loop
if (list[i]>largest) {
largest=list[i];
largeindex=i; //to eliminate the largest later
}
//we have found the largest, stored in largest and its
//index stored in largeindex. Now find the second largest
//ignoring the largest.
if (largeindex==0)
slargest=list[1];
else
slargest=list[0];
for (i=0;i<n;i++)
if (list[i]>slargest && i!=largeindex)
slargest=list[i];
//we have found the second largest
}
//solution #1 ends
That was simple enough. However, were all these comparisons necessary? Let us look closely. Consider the numbers 2,1,3 in this order. To find the largest, this algorithm first compares 2 & 1 and then 2 & 3 (try executing the algorithm by hand with this input). Then, it comes to know that 3 is the largest. Thereafter it tries to find the second largest by comparing 2 & 1. However, this comparison between 2 & 1 has already taken place while finding the largest. So we see that we are repeating work! One wasted comparison in a small example translates to a lot of wasted comparisons in a real scenario.
So we learn that we have to retain (save for future) the results of comparisons from finding the largest and use that to help us when finding the second largest. In our next attempt, we will try to do that so that the number of comparisons required to find the second largest reduce. Is this exercise of reducing a few comparisons necessary? I feel yes, because:
The need to find the largest and the second largest arises in many practical situations. Saving a little time in an oft-used activity can lead to a significant timesaving at the end of the day. Again, in cases where the list of numbers is very large, we can end up with lots of extra time.
At times, comparisons can be really expensive. Let us consider the problem of selecting the prize winners in tournaments where the first and the second players are to be rewarded, such as tennis. In such a situation, each comparison is done by a 'match', which is expensive.
Having decided that we stand to gain by saving on comparisons, we try to find another solution.
Solution #2: Tournament Method.
To find the solution, let us go back to the problem of awarding the best and the second-best players in a team of tennis players. The method used is like this:
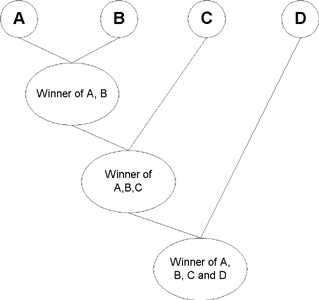
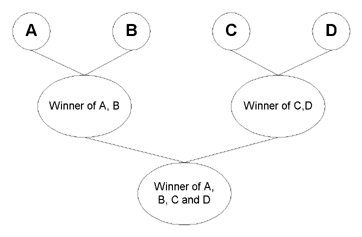
| 1. | Consider the players A, B, C, D,... |
| 2. | Have matches between A & B, C & D,... |
| 3. | Have matches between the winners of match between A & B and C & D,... |
| 4. | ... |
| ... | |
| n. | Continue until only two players remain. |
| n+1. | Have a match between them. The winner is the best player and the loser is the next to best player. |
However, before starting on an algorithm based on this method, let us look closely. We will conduct an experiment. Consider players A, B, C, D, E, E, F, G and H. We will associate with each player a winning capacity number. If two players play a match, the one with a higher number should win (these numbers are just for illustration). Consider A=2, B=3, C=8, D=9, E=6, F=7, G=5 and H=4. Now D and C should be the best and the second-best players since they have the highest numbers. The tournament goes like this:
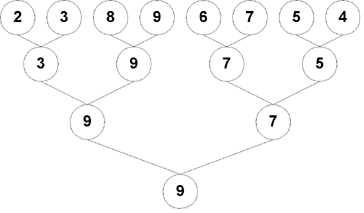
As you can see first prize is correctly awared but for the second prize, F (with number 7) wins rather than C (with number 8). So you see that this algorithm can fail while finding the second largest. Now let us try to modify the algorithm so that this does not happen. First, why did this happen? This happened because two players with nearly same capacity are placed nearby in the tree. So, 8 gets defeated by 9 early in the tree. The problem with the algorithm is that, ANY player defeated by the best player can be the second-best, not always the one who lasts till the end. So, after getting the best player, we must carry out another tournament between the players defeated directly by the best to find the second-best player.
The first person to have thought of the fact that the second prize is awarded unfairly in tennis tournaments was Lewis Carroll, of Alice in Wonderland fame. After his intervention, a system of seeding was introduced, which helps in placing players with similar capacity further away in the tree. This minimizes the chances of the wrong person getting the second prize. Even so, the system can err, although the chances are remote.
However, our program must be foolproof, so will carry out the extra tournament between the direct losers. From the above tree, the players who have been defeated by D(9) are C(8), B(3) and F(7). So we carry out another tournament:
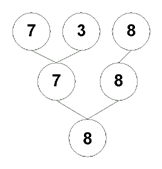
As you can see, C(8) wins. Now we will implement this algorithm. However, before reading on, take a set of numbers and carry out the two tournaments to get a feel of the algorithm.
One implementation problem is that in the first tournament, we must keep track of the players whom the eventual winner is defeating. However, since we don't know who the eventual winner will be, we must keep track of the players getting defeated by all the winners (who have not yet lost). The implementation is shown below:
#include <conio.h>
#include <stdlib.h>
#include <stdio.h>
#define MAXELT 10001
void main() //overhead - read the numbers, print the results.
{
int i=-1,n=0,L[MAXELT],m,s;
char t[10];
void largest_and_second_largest(int a[],int n,int *m,int *s);
do {
if (i!=-1)
L[i++]=n;
else
i++;
printf("\nEnter a number>");
gets(t);
if (sscanf(t,"%d",&n)<1)
break;
} while (1);
largest_and_second_largest(L,i,&m,&s);
printf("\nThe maximum is %d and the second-largest is %d.",m,s);
}
//The action lies here
void largest_and_second_largest(int a[],int n,int *m,int *s)
{
int *I, //stores the losers
size, //stores the current level in the tree
i,j, //indexed
lu, //stores the last compared element in the
//current level
max, //stores the largest number
slarge, //stores the second largest number
sindex; //stores the index of the second largest number
void swap(int *a,int *b);
size=1; lu=-1; //initialize - level one and no number used
I=(int *)malloc(sizeof(int)*n);
for (i=0;i<n;i++) //initialize - no loser yet
I[i]=-1;
for (;;) { //loop until size-1 becomes more than n
i=size-1;
if (i>=n)
break; //loop exit
j=size+i;
if (j>=n && i!=n-1) //if the last element of the array has
j=n-1; //not been considered, use it
if (j>=n)
if (lu<0)
break; //loop exit
else {
j=lu; //store the used number in lu
lu=-1;
}
for (;;) { //another seemingly infinite loop
if (a[i]>a[j]) //swap if out of order
swap(&a[i],&a[j]);
else
I[i]=I[j]; //otherwise, just store in the loser list
I[j]=i;
i=j+size; //next number
if (i>=n)
break; //inner loop exit
else {
j=i+size; //next
if (j>=n && i!=n-1) //if the last element of the array has
j=n-1; //not been considered, use it
if (j>=n)
if (lu>0) {
j=lu; //take in last used
lu=-1; //empty last used
}
else {
lu=i; //if there is no earlier last used, store the
//current number as last used
break;
}
}
}
size=2*size; //move to the next level
}
max=a[n-1]; //largest is found
sindex=I[n-1]; //find the second largest by simple comparison
slarge=a[sindex]; //in the loser list for the maximum
while (sindex!=-1) {
sindex=I[sindex];
if (sindex!=-1 && a[sindex]>slarge)
slarge=a[sindex];
}
*m=max;
*s=slarge;
free(I); //free and return
}
void swap(int *a,int *b) //swap two elements
{
int temp;
temp=*a;
*a=*b;
*b=temp;
}
//solution #2 ends
Using a technique called adversary arguments, it can be shown that there cannot be any algorithm that finds the largest and the second largest in fewer comparisons. While the first algorithm does 2n-3 comparisons for a list with n numbers, the second one does only n+lg(n)-2 (the proof is left to the reader). This algorithm can also be extended to find the k-th largest. To find the k-th largest, simply do k tournaments. The algorithm to find the k-th largest based on tournaments is also optimal.
![]()